Preface
It has been almost a year since I planned to write a weekly report on my blog, and finally, I decided to start writing today. I hope I can publish it in the end.
Why was it delayed until now? I think, on one hand, I have been in the late stage of procrastination, dragging it as long as I could; on the other hand, considering that the weekly report aims to deliver some value rather than merely a life record. Actually, at this moment, I am not sure what specific form this series will take. Although I subscribe to newsletters from some big shots like Ali Abdaal, compared to their life experiences, reading volume, and reflections on surrounding things, I currently have little to offer, which invisibly increases the pressure of writing.
As for the content, I will initially lean towards some reflections on life, as it is an easy brain activity to do. There are always things happening in the real world, from small conflicts between passengers and drivers on the way to work to big debates among big shots on social media. Whether it’s personal experience or observation, if you can reflect more on them, you can still piece together a lot of content. However, I am also exploring this “discover-reflect-record” process, which may be characterized by skimming the surface or general discussions in the near future, so please be lenient.
Besides reflecting on life, I will also record some content heard (podcasts) or seen (articles), mainly leaning towards technology and business. I consider myself like a person picking up shells on the beach of life. The sea rises and falls, and some tiny things are always forgotten. I hope these things can be discovered and subtly influence my ordinary life. Of course, if they also happen to inspire you, that would be even better.1
Facing choices
I was a bit surprised when I learned from a podcast that an adult makes at least 35,0002 choices a day. But on second thought, it’s not surprising because most of them are automatically filtered by our brains, or sometimes choices are made so quickly that we don’t even realize it. And this automatic filtering, or more precisely “taking things for granted” is what I want to talk about briefly. Think about how often do we wonder in life, “Why did I do that just now, why did I say that”. Maybe most people make choices without knowing how to choose, hastily but stagnantly. Many times, our unhappiness is probably because of the absurd choices we made.
How to change
Currently, I can’t say I have a solution, but being aware of those moments of choice, slowing down, and letting rationality intervene instead of taking things for granted, I think would make a significant improvement. “Taking things for granted” is, to some extent, a form of laziness, lazy in thinking, lazy in decision-making. So, when you encounter unhappiness next time, think about what just happened, can you slow down a bit when making a choice, and can you avoid these unhappiness next time.
Moreover, besides myself, I also observe the people around me and see how they make choices, for example:
- Facing an elderly person taking a seat during peak hours on the way to work
- A middle-aged woman complaining about not buying a ticket in advance
- The cashier at Mr. Rice with a bad attitude
Vector database
This week, when browsing Bilibili, I came across the concept of vector databases. Here is a brief rough discussion, the specific content still needs further research.
Vector databases have become popular due to recent large language models. Traditional databases, such as an Excel table, store structured data, but the explosive growth of modern information technology has generated a lot of unstructured data, common examples being images and videos. How to retrieve this data poses a challenge to large models.
A video contains many features and attributes, such as video duration, related topics, audience, likes, etc. If these attributes are stripped and given values (evaluations), then multiple attributes form a vector space, and the video has a coordinate in this space, a process also known as data vectorization.
Similar data bodies, when vectorized, will be closer in the vector space, which is very suitable for recommendation algorithms.
Why data should be vectorized
Because vector operations are what computers are best at.
Vectorization and tagging system
Some time ago, I was studying my tagging system, such as how to tag notes, emails, favorite web pages, etc. Tagging is, to some extent, similar to vectorization. The tagging system can also be seen as a weakened version of a vector database, aiming to achieve better retrieval and association of content through attribute extraction and abstraction.
Edge computing
Recently, I have been playing with the TI AM62A board and learning about the concept of edge computing. Edge computing has been heard more or less in technology channels before. Unlike cloud computing, edge computing focuses on IoT devices or embedded fields, including edge AI.
Edge computing allows devices in remote locations to process data at the “edge” of the network, either by the device or a local server. And when data needs to be processed in the central datacenter, only the most important data is transmitted, thereby minimizing latency.
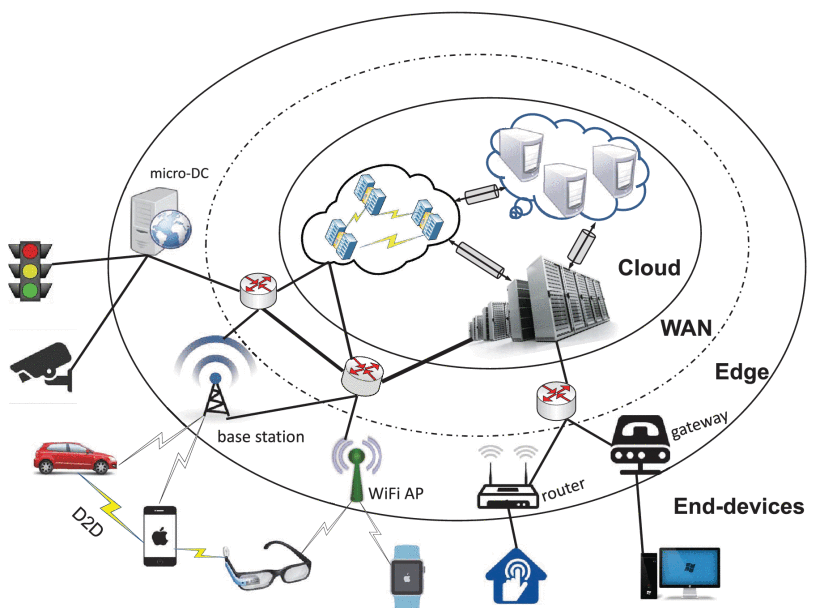
Image source: Edge Intelligence
The development of this technology mainly considers that the data collected by edge devices (especially various sensors) is redundant. If the data is directly uploaded to the data center for cloud computing, it would consume a lot of bandwidth. At the same time, edge devices are generally battery-driven, with power consumption being a priority. So it is best to clean and process the data at the edge end, and only upload it to the cloud when necessary. This also avoids some data privacy issues.
As the last mile technology of artificial intelligence, those interested can refer to this paper for further study.
Performance disclosure
In the past two weeks, the Shenzhen Main Board and the ChiNext Board have welcomed the intensive semi-annual report preview disclosure3. You can look at the pre-increase stocks in the bottom range if you are a short-term speculative player. However, it was only until July 15th, now it’s over.
Inescapable daily record
This part will record some work and study progress this week, as well as list books and audio-visual materials, fun things purchased, etc. The content will be relatively trivial.
Technical learning
- Preparing for the TI Edge AI group presentation with SK-AM62A
- Learned the general development process of Linux u-Boot
- Rebuilt the Git server using Gitea + PostgreSQL
- Set up an internal knowledge network using Hugo + IIS
- Ran some DL models using Miniconda
- Re-studied Git and WSL technologies
Books and podcasts4
- 来都来了 - No.152 - 嘉宾叶斌:既要又要的人生,真的是你想要的吗?
- 商业就是这样 - Vol.118 英伟达如何变得“不可替代”?
- What’s Next|科技早知道 - S7E19|一亿人支持 Meta 新产品「像素级拷贝」Twitter
- She Said
- The Logic Behind the Hot Vector Database
- Vector Database Technology Appreciation
Investment and fitness
- Completed 4 rowing machine workouts, totaling 82 minutes
- Stock return last week was +1.36%, underperforming the market +1.92%
-
Updated on 2024-09-27: This part has been moved to the “Toots” for a better presentation ↩︎
-
Investment must-have: Performance Disclosure Schedule - Xueqiu ↩︎
-
Personally, I believe listening to podcasts is a great way to acquire firsthand knowledge, especially interviews with industry insiders ↩︎
Related Posts
